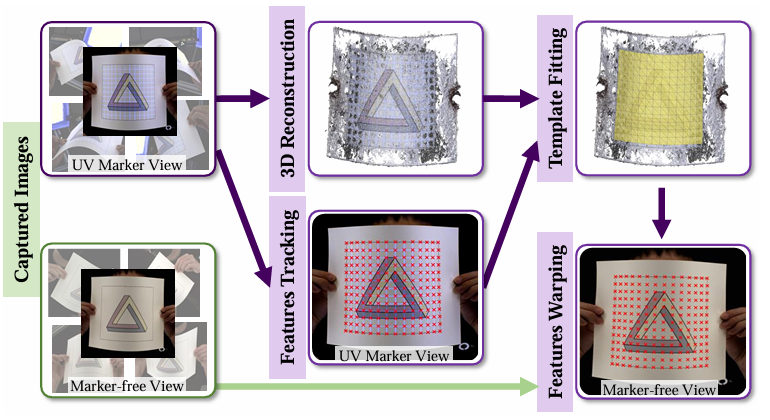
"Invisible" Markers
We use "invisble" markers to introduce features to surfaces, regardless of its original texture. The "invisible" markers are made with UV fluorescent dyes that are only visible under UV lighting. Since they are invisible under visible light, the surface appearance remains untouched in normal lighting conditions.
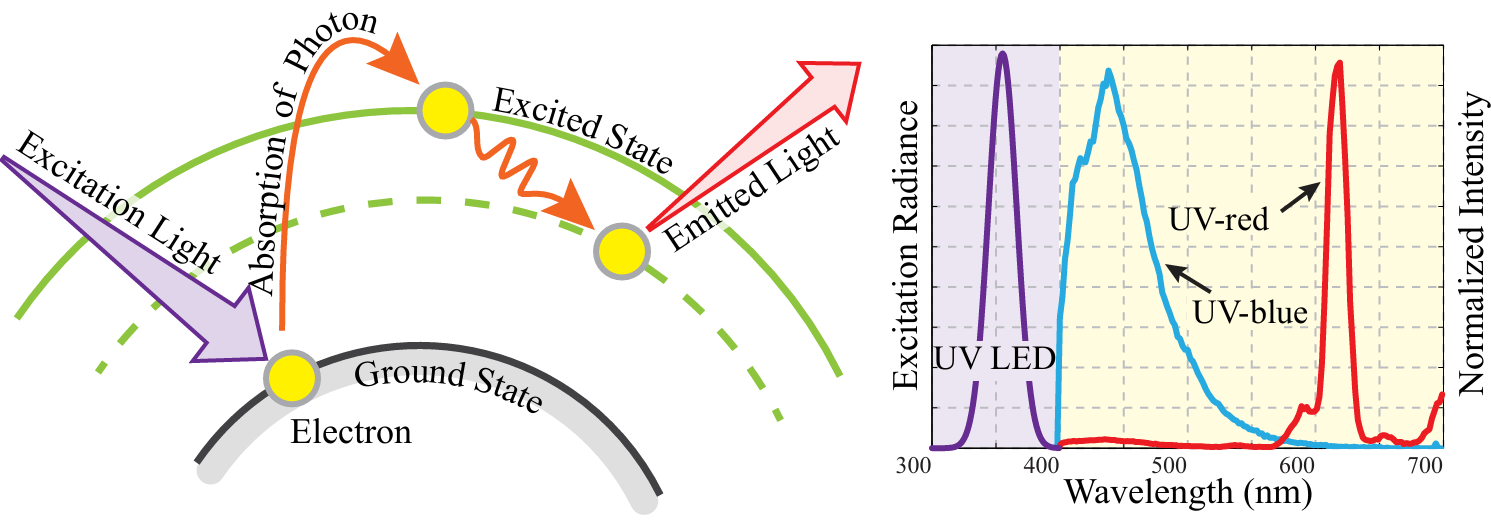
We use different patterns for different types objects. Here are some example patterns we use.